Shows just fullsize Image with hotkeys & without pop-ups on many image-hosting sites
Was the page you opened images perhaps the main page of the site and is there perhaps a message in the browser console saying "Handy Image: userscript stopped itself from running INTENTIONALLY: cuz your previous page is websites mainpage so you probably have just uploaded a picture yourself"?
Update to todays version, I have improved that moment there so you can at least open in new tabs images from the main page safely
Alternatively using https://rekall.me/? instead of just https://rekall.me/ would work too
This is a post I used for testing:
https://rekall.me/post/708047869572186112/
The console warning it produces is the default "HJI is running on a custom website", and often this works, followed by "showing biggest image". However with aforementioned problematic posts such as this:
https://rekall.me/post/707957263253602304/
The image isn't displayed, so the script can't find it.
The /post/* match was to avoid matching the /archive/ page, which broke with my band-aid fix.
Today's version seems to have the same console warnings, and same limitation, re the broken posts.
There's also the issue that it doesn't cope with multi-image posts, but neither the "tumblr.com" case nor the default generic do, so that would require additional logic.
Also, after further testing on another tumblr domain, the "INTENTIONALLY" warning appears when opening posts from the main blog page, and accordingly the script doesn't execute, which doesn't seem intended, as it's not the behavior on other image hosts.
EDIT: This is true with the script before and after the most recent update.
However with aforementioned problematic posts such as this: https://rekall.me/post/707957263253602304/ The image isn't displayed, so the script can't find it.
If there is no image... what do you even want the script to do about it? draw a new image for you? this is not that kind of Ai-painter software :D

Also, after further testing on another tumblr domain, the "INTENTIONALLY" warning appears when opening posts from the main blog page, and accordingly the script doesn't execute, which doesn't seem intended, as it's not the behavior on other image hosts.
the only way the script can make a guess that the user uploaded something previously is by checking that referrer (previous page) was the mainpage of the site and that the back to prev page button is active (the page isn't opened in the new tab)
However with aforementioned problematic posts such as this:
https://rekall.me/post/707957263253602304/
The image isn't displayed, so the script can't find it.If there is no image... what do you even want the script to do about it? draw a new image for you? this is not that kind of Ai-painter software :D
The image is specified in the HTML, but there's probably some custom JS which breaks its display. The query selector for the "tumblr.com" case ('meta[property="og:image"]') finds and displays it properly; it just doesn't match it because of the custom domain, which is what I changed for my band-aid.
Also, after further testing on another tumblr domain, the "INTENTIONALLY" warning appears when opening posts from the main blog page, and accordingly the script doesn't execute, which doesn't seem intended, as it's not the behavior on other image hosts.
the only way the script can make a guess that the user uploaded something previously is by checking that referrer (previous page) was the mainpage of the site and that the back to prev page button is active (the page isn't opened in the new tab)
In the recent versions of the script, it also stops itself on new tabs opened from the main page, where the back button is inactive.
EDIT: Never mind, I currently had the wrong version.
The image is specified in the HTML, but there's probably some custom JS which breaks its display.
You should probably tell the websites author that his images are invisible, perhaps you're the first person ever to see them because others aren't hackers to dig the hidden images out of the HTML code...
The image is specified in the HTML, but there's probably some custom JS which breaks its display.
You should probably tell the websites author that his images are invisible, perhaps you're the first person ever to see them because others aren't hackers to dig the hidden images out of the HTML code...
The thumbnails show up on the /archive/ page, which is how I usually browse pages. I will try to contact them, but since your script already fixes this for "tumblr.com" subdomains, I just wondered if there was an easy way to apply it to custom domains using the same backend.
There's also the issue of posts with multiple images, of which the script only displays one. Are there any other hosts that have posed that problem?
There's also the issue of posts with multiple images, of which the script only displays one.
I guess that'd be only a problem for added custom websites since for specific domain extractors there are checks for that Though, if images are of exact same resolutions - custom extractor could check for that and don't do anything - is that the case here?
There's also the issue of posts with multiple images, of which the script only displays one.
I guess that'd be only a problem for added custom websites since for specific domain extractors there are checks for that
Though, if images are of exact same resolutions - custom extractor could check for that and don't do anything - is that the case here?
For testing this I used this link: https://hardsci-fi.tumblr.com/post/706879888812097536
Which should be processed as the "dynamic subdomain" case for "tumblr.com". That part of the script, document.querySelector('meta[property="og:image"]'), only returns the first image, but there's multiple which match that property.
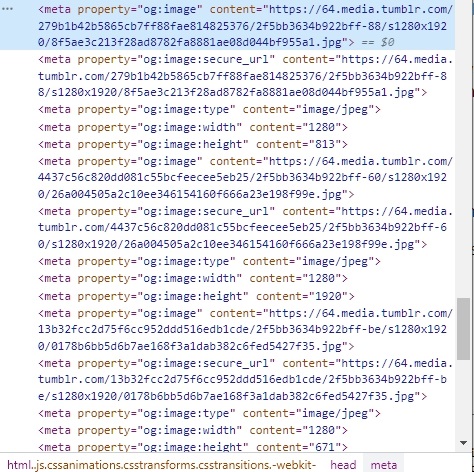
Looks like tumblr had a site update, but none of the users bothered to make a bug report about it (no surprise since tumblr barely has any users left)
latest version should account for galleries there now
You're right, there's not many, and probably only one or two developers.
Thanks for the update; seems to work just fine.
The simplest way I figured out to handle custom domains is to add an explicit case setting 'host' to a tumblr subdomain so it gets processed by the "dynamic subdomain" switch. Previously I tried dynamic detection with a Selector, but there's probably not enough people using custom tumblr domains to bother implementing that lol.
EDIT: picture
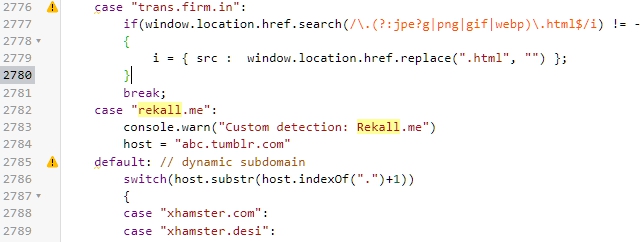
Also just realized the script has explicit matches, so dynamic detection wouldn't matter anyway; I feel stupid.
But doing a little more testing I found that video posts also contain an image, so the script will just fullscreen that. I added the following little tweak to point it at the video instead:case "media.tumblr.com":
f = document.querySelectorAll('meta[property="og:image"]');
g = document.querySelectorAll('meta[property="og:video"]');
if(g.length > 0){
i = g[0];
i.src = g[0].content;
break
}
example video post: https://hardsci-fi.tumblr.com/post/641572020009795584/
added video support into latest version
Thanks.

Custom domain hosts using Tumblr backend; detection possible?
I added a user match for https://rekall.me/post/*, as some posts don't properly display their content, even in an unmodified window. The default "HJI is running on a custom website" (2854) extractor predictably didn't work, as the domain uses the Tumblr back-end (content=*media.tumblr.com, etc). However because the host is not a subdomain of tumblr.com, it isn't handled by the "dynamic subdomain" (2782) switch. I resolved this by copying the "media.tumblr.com" case before that switch, replacing the domain.
My query is if it's sensible to have a generic extractor for these cases, custom hosts which use a common back-end, or if that would introduce excessive complication? Ie, an alternative to "per-host image detection" (1140).
Thanks for continuing development; it remains the best script of its type.